# Le modèle OMOP
OMOP-CDM (opens new window) (Observational medical outcomes partnership - Common Data Model) est un modèle relationnel de bases de données de santé, qui a pour objectif de rendre interopérables différentes bases d'analyse en santé, qu'elles soient cliniques ou médico-administratives, pour répondre au besoin de mener des études observationnelles, fédérées et à grande échelle.
L'interopérabilité se traduit concrètement par la possibilité de partage d'outils, de méthodes, d'études et de programmes entre les organismes disposant d'une base au format OMOP.
# Origine : Verrou dans l’utilisation des données de santé à l’échelle internationale
A l’échelle internationale, il existe différents types de bases de données de santé, comportant souvent des données disparates au niveau du patient. Ces bases de données sont aussi diverses que les systèmes de santé eux-mêmes, reflétant différentes populations, différents milieux de soins et différents processus de saisie des données. Pourtant, les données relatives aux soins de santé peuvent transformer notre compréhension de la santé, des maladies et de leurs conséquences, mais elles sont actuellement dispersées dans de multiples institutions et pays, stockées dans des formats différents et soumises à des règles différentes. Il est donc très difficile d'utiliser pleinement ces données de manière transversale.
Face à ce constat, un partenariat public-privé appelé OMOP (Observational Medical Outcomes Partnership), présidé par la Food and Drug Administration (opens new window) aux États-Unis et financé par un consortium de sociétés pharmaceutiques a été créé en 2008.
OMOP a collaboré avec des chercheurs universitaires et des partenaires de données sur la santé pour établir un programme de recherche visant à faire progresser la surveillance active de la sécurité des produits médicaux en utilisant des données d'observation des soins de santé aux Etats-Unis.
# Création d’un modèle de données commun OMOP
Pour remédier à la complexité technique des projets de recherche due à des bases de données disparates, OMOP a conçu le modèle de données commun éponyme (appelé OMOP-CDM) comme un mécanisme permettant de normaliser la structure, le contenu et la sémantique des données d'observation et de rendre possible l'écriture de codes d'analyse statistique uniques qui pourraient être réutilisés sur chaque base de données.
Après conversion de premières bases de données dans ce format, il a été démontré qu'il était possible d'établir un modèle de données commun et des vocabulaires normalisés qui pourraient accueillir différents types de données provenant de différents environnements de soins et représentés par différents vocabulaires sources d'une manière qui pourrait faciliter la collaboration entre les établissements et chercheurs au niveau international.
# Parties prenantes
Le modèle commun OMOP est maintenu et développé au sein de la communauté open-source OHDSI (opens new window) (Observational Health Data Sciences and Informatics, acroynyme se prononcant "Odyssée").
Le format OMOP est promu en Europe par le Réseau européen de données et de preuves en matière de santé (EHDEN)

En novembre 2023, 187 sources de données (opens new window) sont converties ou en cours de conversion vers le format OMOP dans 29 pays d'Europe à l'aide du réseau EHDEN.
Le format OMOP est soutenu par des universités (ex: Columbia (opens new window)), des industriels (ex: Iqvia (opens new window)) et des institutions (ex: USA, Corée du Sud, Union Européenne, etc).
# Structure
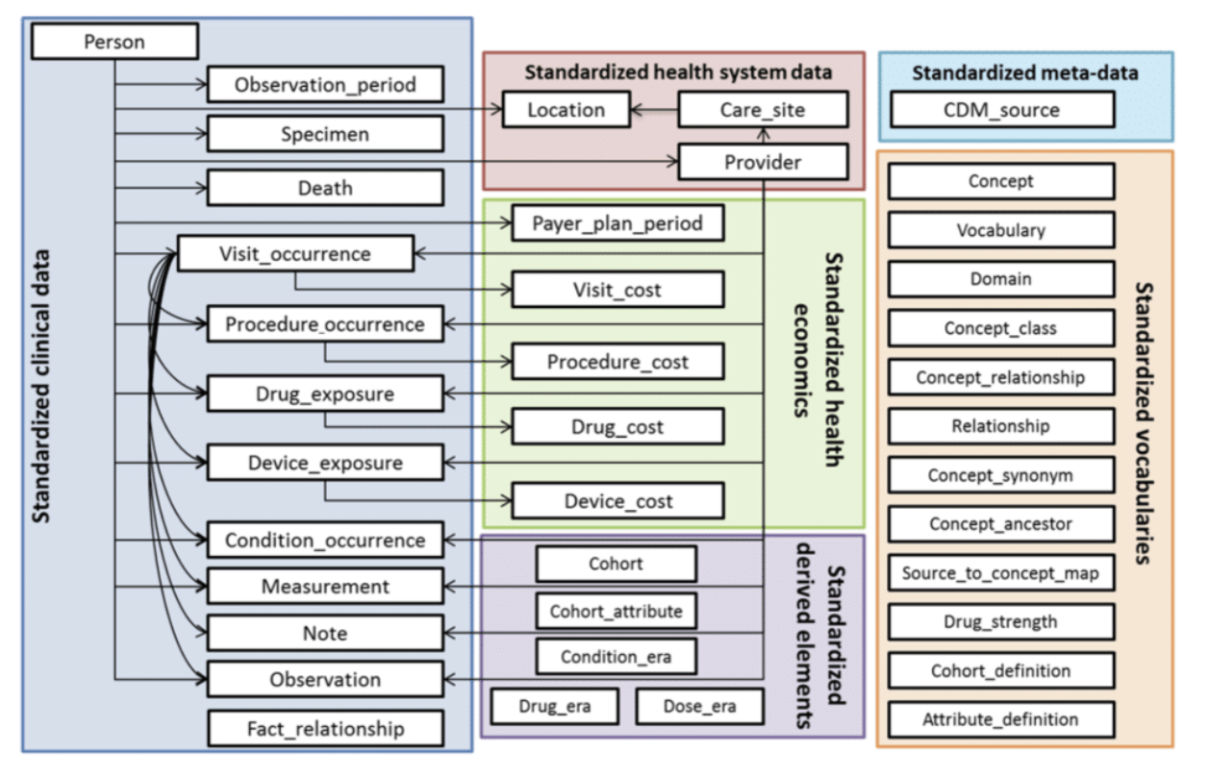
Le modèle OMOP est centré autour de la table PERSON qui référence tous les patients.
Pour chaque patient, la liste de toutes ses interactions avec le système de santé est contenue dans la table visit_occurrence. Les tables procedure_occurrence, drug_exposure, device_exposure, condition_occurrence, measurement, note et observation contiennent tous les événements médicaux intervenus pendant les visites, auxquelles elles font référence.
Des informations sur les établissements et les professionnels de santé sont contenues dans les tables location, care_site et provider (Domaine en rouge).
Il est possible de capter les informations sur les coûts engendrés par les soins dans les tables payer_plan_period et *_cost (Domaine en vert).
12 tables contiennent les informations sur les codes des nomenclatures utilisées pour décrire les donnés, et leurs relations (Domaine en orange).
Pour finir, les tables du domaine en violet sont créées à partir d'autres tables. Les tables *_era permettent d'identifier des périodes de traitement ou d'affection pathologiques et les tables cohort_* permettent d'identifier des cohortes.
# Références
G. Hripcsak et al., « Observational Health Data Sciences and Informatics (OHDSI): Opportunities for Observational Researchers (opens new window) », Stud Health Technol Inform, vol. 216, p. 574‑578, 2015.
Site d’OHDSI (opens new window), la fondation promotteur d’OMOP