# Données de synthèse du lab santé de la DREES
Attention
Pour des raisons techniques liées aux licences acceptées par Gitlab, ces données sont temporairement indisponibles au téléchargement direct. Elles peuvent toutefois être générées à partir des outils indiqués ci-dessous. Si vous souhaitez accéder au jeu de données sans le générer, vous pouvez contacter le Health Data Hub à l'adresse opensource@health-data-hub.fr
Ce jeu de données est généré grâce à la librairie tsfaker (opens new window) à partir du schéma formel (opens new window) du SNDS et il est disponible dans le dépôt GitLab du Health Data Hub dans le dossier synthetic-snds. Son utilisation est libre suivant la licence ouverte (opens new window). Ces données sont identiques aux données tels que les organismes ayant un accès permanent y accèdent. La différence entre un accès permanent et une extraction DEMEX (extractions du SNDS délivrées par la CNAM) étant l’identifiant bénéficiaire dans le DCIR : BEN_NIR_PSA pour les accès permanent et NUM_ENQ pour les extractions DEMEX.
WARNING
Ces données sont factices, et ne contiennent aucune information personnelle ni aucune cohérence médicale.
# Où trouver le SNDS synthétique ?
Pour visualiser les données synthétiques, le plus simple est actuellement de parcourir le dossier schemas du projet GitLab SNDS synthétiques (opens new window).
Voici par exemple 10 lignes synthétiques de la table ER_PHA_F du DCIR
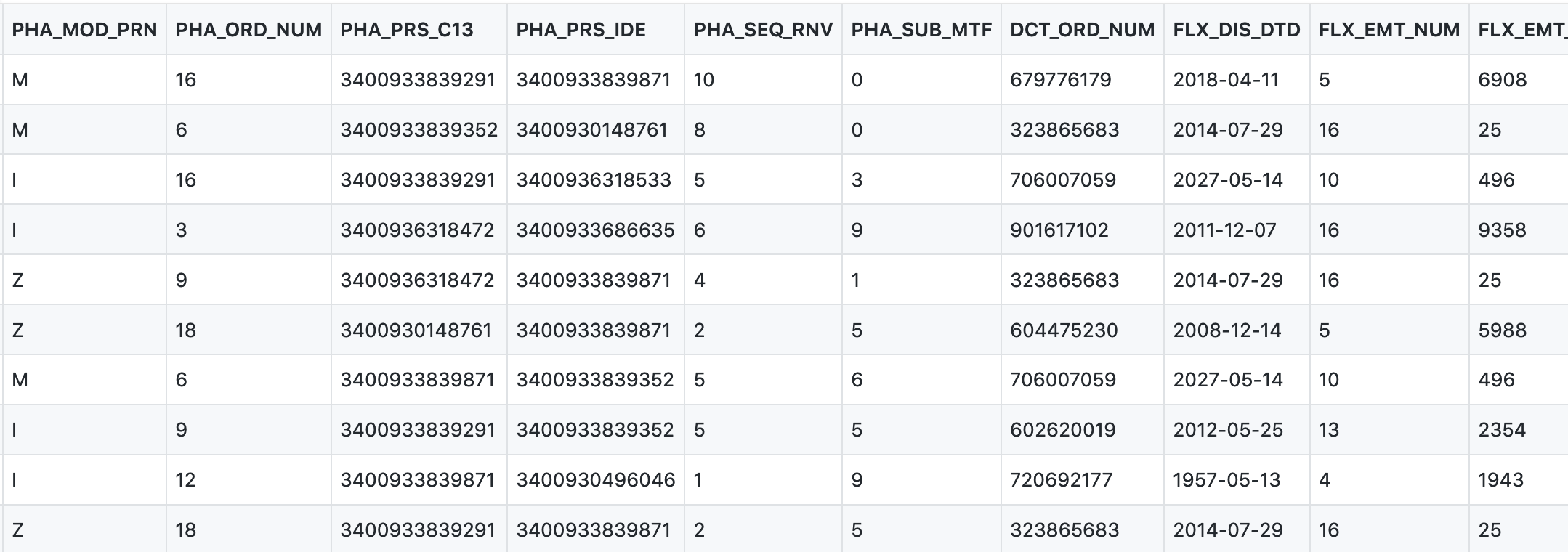{kind=link}
Vous pouvez également télécharger une archive zip du projet (opens new window).
# Génération des données
Les données synthétiques sont générées à partir du schéma formel du SNDS (opens new window), avec la librairie Python tsfaker (opens new window)[1].
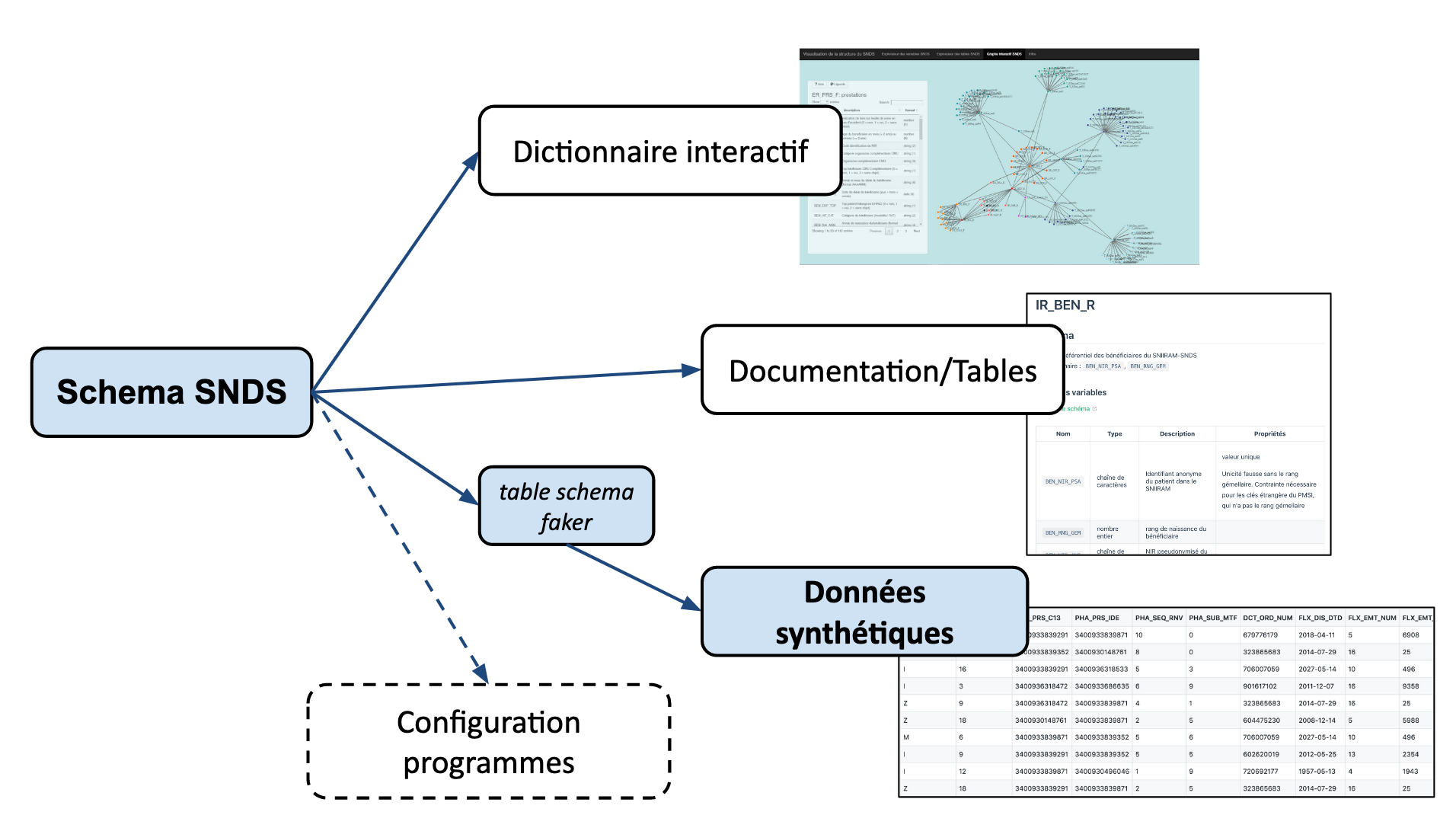
À chaque modification du schéma, de nouvelles données synthétiques sont automatiquement générées sur le projet SNDS synthétique (opens new window).
Seulement 10 lignes sont générées pour chaque table, de façon à limiter la taille du projet. Il est possible de générer plus de lignes par table en suivant les instructions en fin du README du projet.
# Intérêts
Le SNDS synthétique a pour principal intérêt d'être libre de réutilisation, car il ne contient aucune donnée personnelle.
Les données respectent
- la structure des tables,
- les jointures entre tables,
- le type des variables,
- les valeurs des variables associées à des nomenclatures,
- des contraintes simples sur les variables (min, max, longueur).
Ces données peuvent être utilisées pour apprendre à manipuler le SNDS ou préparer un ETL (Extract,Transform,Load) dans le cadre d'une transformation du modèle de données (passage à OMOP-CDM par exemple).
# Limites
# Absence d'informations statistiques
Les données synthétiques ne contiennent pas d'information statistiques. Il est donc impossible de réaliser des analyses à partir de ces données.
Note
Il serait facile d'ajouter des distributions univariés sur les variables, en ajoutant leur fréquence d'apparition dans les nomenclatures. Une petite évolution de la librairie tsfaker serait alors nécessaire (cf issue 5 (opens new window)).
En particulier, les données ne respectent aucune règle logique entre paires de variables. Une date de début peut par exemple être postérieure à une date de fin. Il serait possible d'ajouter de telles contraintes par un traitement a posteriori.
# Pas de version par année
Le schéma des tables évolue chaque année, avec l'ajout ou la suppression de tables et variables.
Ces informations sont actuellement présentes dans le schéma SNDS, mais de façon trop incomplète pour générer un SNDS synthétiques pour chaque année.
# Erreurs dans le schéma
Le schéma des tables est imparfait et incomplet. Ces erreurs sont directement visibles dans les données synthétiques.
Il manque en particulier de nombreuses tables de nomenclatures, qui indiquent les valeurs prises par les variables, avec les libellés correspondant aux codes employés.
# Amélioration des données synthétiques
Vous pouvez contribuer à améliorer les données synthétiques en améliorant le schéma formel du SNDS sur le projet schema-snds (opens new window). Vous pouvez proposer des merge-request pour ajouter des contraintes, corriger les types, ou compléter les nomenclatures.
Des liens directs pour éditer les schémas sont disponibles sur le dictionnaire interactif (opens new window), et sur les pages de la section table de cette documentation.
Si vous souhaitez proposer d'autres types d'améliorations, vous pouvez ouvrir des issues sur le projet schema-snds (opens new window), ou sur le projet tsfaker (opens new window) si cela concerne la procédure de génération.
# Citer les données
Pour toute publication autour des travaux réalisés sur ces données, merci de citer la base de données de la manière suivante : « SNDS synthétique développé par l’équipe du lab santé de la DREES »
La librairie
tsfakera été développée par Pierre-Alain Jachiet pour le SNDS synthétiques. Sa spécificité par rapport à d'autres libraires équivalentes est de s'appuyer sur le standard Table-Schema, et de bien gérer un grand nombre de clés étrangères. ↩︎